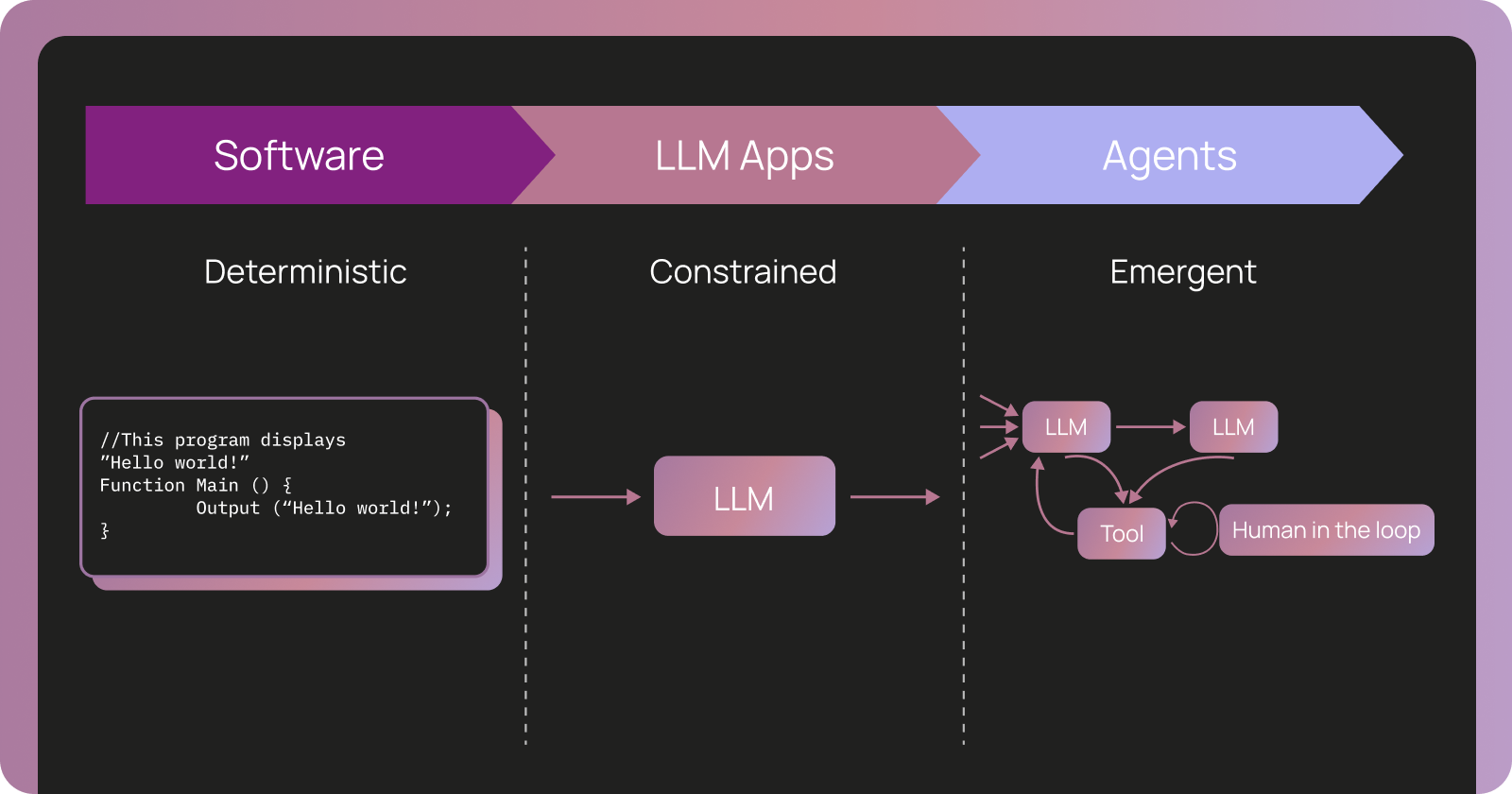
Agent evaluation ≠ software evaluation
Agent 工程正在成为热点,但由于 LLM 本身具有不确定性,如何评估 Agent 能力逐渐成为关键问题。传统软件出错时,我们可以查看日志、追踪调用栈、定位失败代码行。但 Agent 的错误并不总是来自代码。比如,一个客服 Agent 在两分钟内执行了 200 步操作,却在中途做出了错误判断,这类失败往往没有明确的栈痕迹,因为出问题的不是代码,而是推理过程。因此,Agent 调试的重点,需要从“调试代码”转向“调试推理”。
当出现问题时,你找不到一行代码失败。你会问:
- 为什么Agent决定在 200 步中的第 23 步调用
edit_file而不是read_file? - 当时的具体上下文和prompt促使了这个决定?
- 在这两分钟、200步的轨迹中,Agent偏离了哪里?
传统的追踪工具无法回答这些问题。200步的追踪对人类来说过于庞大,而传统追踪工具无法捕捉每个决策背后的推理背景;它们只记录了调用了哪些服务以及每个服务所用的时间。
Agent observability可以使用三个核心指标来捕捉非确定性推理:
- Runs:单次执行步骤
一次 Run 通常对应一次 LLM 调用及其输入输出,用来查看 Agent 在某一步“看到了什么、想了什么、做了什么”。调试时,可以关注:Prompt 中包含哪些信息?可用工具有哪些?Agent 为什么选择这个动作?评估时,可以为该步骤设置断言:是否调用了正确工具?参数是否合理?输出是否符合预期?
- Traces:完整执行轨迹
Trace 记录一次完整的 Agent 执行过程,包含所有 Runs、工具调用、参数、结果以及上下文变化。它能帮助我们从整体上复盘 Agent 的决策链路。但对于复杂、长时间运行的 Agent,Trace 可能非常庞大,甚至达到数百 MB,因此需要良好的筛选、压缩和可视化能力。
- Threads:多回合对话上下文
Thread 用来把多个 Trace 按时间组织起来,适合观察跨会话、跨任务的 Agent 行为。它不仅记录用户与 Agent 的连续交互,还能展示 Agent 的记忆、文件、状态等如何随时间演化。对于持续几分钟、几小时甚至几天的长周期任务,Thread 是理解 Agent 长程行为的重要入口。
这些工具使用与传统可观测性相同的概念(如traces, spans),但捕捉的是推理上下文,而非服务调用和时间。并且你可以在不同粒度层级评估代理,这些粒度与可观测原语 1:1 映射。 你正在评估的内容决定了你需要哪种原语:
-
Single-step evaluation :关注 Agent 在某一个具体步骤中是否做出了正确决策。例如:是否选择了正确工具?参数是否合理?这一步输出是否符合预期?
-
Full-turn evaluation :关注 Agent 是否完整、正确地完成了一次任务。例如:执行路径是否合理?工具调用顺序是否正确?最终结果是否满足用户目标?
-
Multi-turn evaluation :关注 Agent 是否能在多轮交互中保持上下文一致性。例如:是否记住了用户偏好?是否延续了前文状态?是否在长对话中保持目标不偏移?
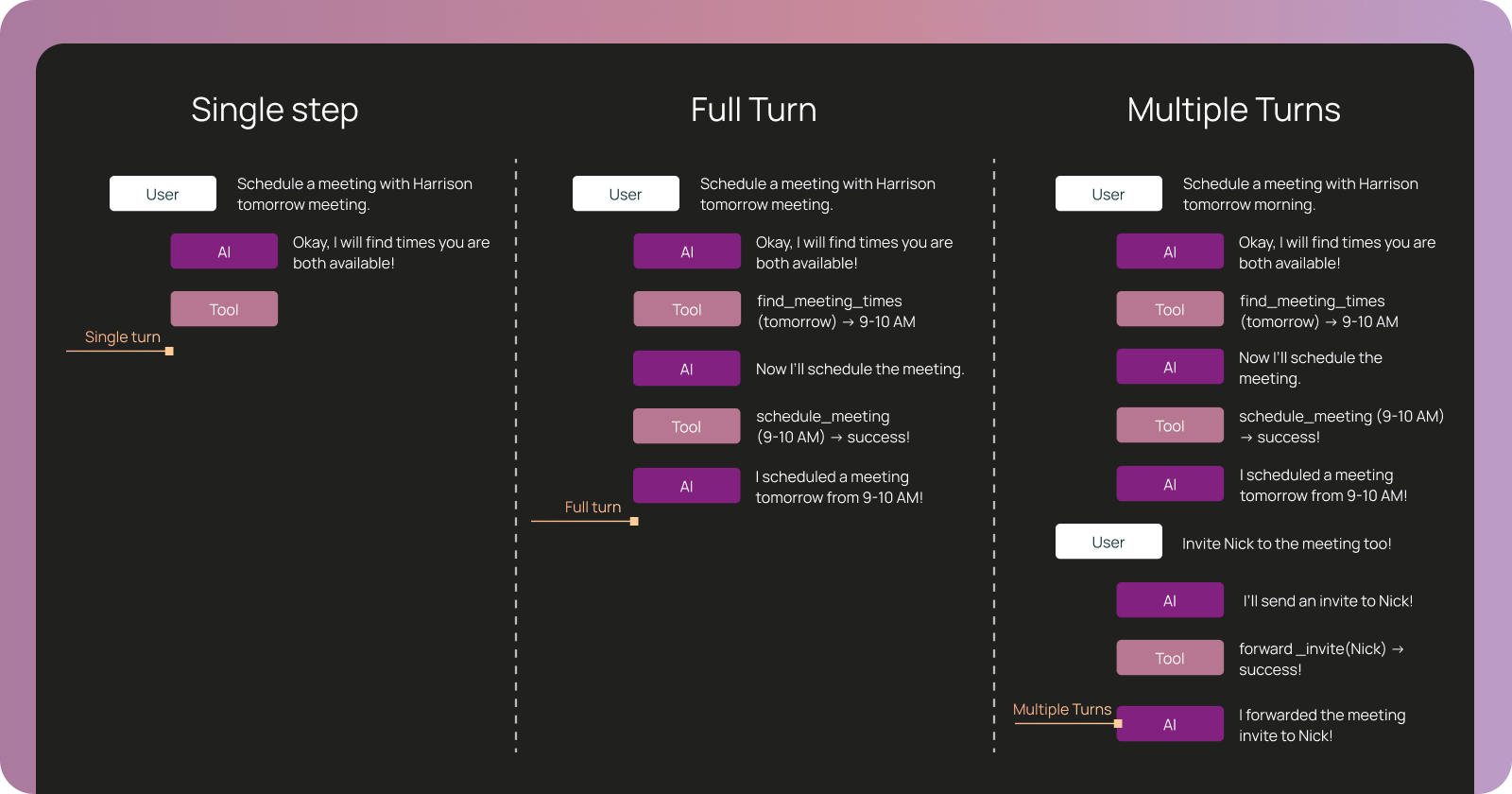
How and when to choose what granularity to evaluate your agent at
评估 Agent 没有唯一正确的粒度。多数生产系统会组合使用多种评估方式:用 Trace 级评估测试核心工作流,用 Run 级评估覆盖已知故障模式,用 Thread 级评估验证多轮有状态交互:
-
Trace 级评估对应一次完整任务。输入通常就是用户给 Agent 的任务,因此比较容易构造测试集。难点在于:预期输出往往不唯一,且很难用程序自动判断结果是否正确。所以早期阶段常见做法是:先自动运行测试,但暂时依赖人工或半自动方式评分。
-
Run 级评估只关注单个步骤,通常对应一次模型调用或一次工具调用。由于范围更小,往往可以通过工具选择、参数、返回结果等规则进行自动评分。需要注意的是,如果 Agent 内部结构频繁变化,例如工具列表、调用顺序、Prompt 结构发生调整,这类评估很容易失效。因此,它更适合在 Agent 架构相对稳定后建设。
-
Thread 级评估关注多轮交互中的状态保持与上下文延续。它需要设计一系列连续输入,而且这些输入往往只有在 Agent 前几轮表现正确时才有意义。同时,多轮结果也更难自动评分。因此,这是生产中最少见、但对长期任务和有记忆 Agent 最重要的评估类型。

agent输出直到你在生产环境中运行时才会完全显现, 这意味着评估代理时也不同于传统软件。
-
Offline Evaluation:上线前评估 Offline Evaluation 类似传统软件中的单元测试。你需要提前准备输入数据集,也可以准备标准答案或参考输出进行对比。根据 Agent 运行和评分成本,这类评估可以在每次提交时执行,也可以在上线前集中执行。如果评估频率较高,建议加入缓存机制,避免重复调用模型。通常大家说的 “Eval”,主要指的就是 Offline Evaluation。
-
Online Evaluation:生产中评估 由于 Agent 的真实表现往往只有运行后才知道,因此需要在生产数据上进行在线评估。Online Evaluation 通常是无参考答案的,只能基于真实交互、工具调用、用户反馈或行为指标判断 Agent 表现。这类评估适合持续监控生产环境中的质量变化和异常模式。
-
Ad-hoc Evaluation:探索式评估 Agent 的输入和行为空间非常开放,很多问题无法提前设计测试集。生产中积累大量 Trace 后,可以针对已发生的行为进行临时分析和回放测试。这种探索式评估有助于发现未知失败模式,也是理解和改进 Agent 的重要方式。

How to build, run, and ship agent evals
Dataset construction
Ensure every task is unambiguous, with a reference solution that proves it’s solvable 在设计评估任务时,输入必须尽量明确、可执行、可验证。如果 Agent 无法成功是因为信息缺失、约束冲突或任务本身不可完成,那么问题不在 Agent,而在测试任务设计。因此,每个评估任务都应该提供一个参考答案。这样既能证明任务本身是可解决的,也能为后续自动评分或人工评分提供基准。 比如,模糊任务:“帮我找个飞往纽约的好航班。”明确任务:“查找从旧金山国际机场飞往 JFK 的往返航班:12 月 15 日至 17 日期间出发,12 月 22 日返回,经济舱,价格低于 400 美元。”
Test both positive cases (behavior should occur) and negative cases (behavior should not occur) 如果只测试“Agent 该搜索时是否搜索”,很容易把它优化成“什么都搜索”的系统。这样的评估会制造错误激励。因此,评估集里也必须加入负例:不仅测试 Agent 什么时候应该行动,也要测试它什么时候不该行动;不仅验证预期行为,也要包含能够反驳假设的案例。
Ensure dataset structure matches your chosen evaluation level
- Run-level (single-step) 评估需要引用工具调用或决策
- Trace-level (full-turn) 评估需要预期的最终输出和/或状态变化
- Thread-level (multi-turn) 评估需要多回合对话序列,并期望上下文保持
Generate seed examples if you lack production data 实用建议:20-50 个你有信心的手工复习样本,会胜过你未验证的数百个合成样本。这里质量胜于数量!
Grader design
Select specialized graders per evaluation dimension 当任务存在客观正确答案时,应优先使用基于代码的评估器。对于这类任务,LLM-as-a-Judge 往往不够稳定,同一结果可能在不同评审中得到不同判断,从而掩盖真实的性能回退。相比之下,确定性的代码比较能减少评分波动,提供更可靠的评估信号。因此,LLM 评审更适合用于开放性、主观性较强的任务。
同时,不要试图设计一个“大而全”的正确性评估器。更好的做法是将评估拆解为多个维度,并为每个维度设计专门的评分器。例如,Witan Labs 团队将评估拆分为内容准确性、结构完整性、视觉格式、公式场景和文本质量五个维度,并分别设置对应的判断标准和通过阈值。这样不仅能判断 Agent 是否失败,还能更清楚地定位失败发生在哪个环节。
Prefer binary pass/fail over numeric scales 1–5 分量表看似更细致,但相邻分数之间往往存在主观差异,也需要更大的样本量才能获得统计显著性。相比之下,二元评分更清晰:Agent 要么成功,要么失败。对于复杂任务,不必依赖一个模糊的总分,而是可以将其拆解为多个二元检查项。例如,是否调用了正确工具、参数是否正确、结果是否满足约束、是否完成最终目标。这样既能降低评分歧义,也更容易定位失败原因。当然,在使用 LLM-as-a-Judge 时,0–5 这类短量表有时更容易与人类偏好对齐。但对于人工审查和快速迭代来说,二元评分通常更简单、更稳定,也更适合持续评估。
Grade the outcome, not the exact path, and build in partial credit for incremental progress Agent 可能会找到更灵活、更有创造性的解决方案。正如 Anthropic 在 Demystifying Evals 中提到的,评估时不要只关注 Agent 走了哪条路径,而要关注它最终产出了什么。如果你强制要求 Agent 必须按照 A→B→C 的顺序调用工具,就可能惩罚那些用更高效方式完成任务的 Agent。因此,评估标准应尽量围绕最终结果设计。例如,与其检查“是否在 create_event 之前调用了 check_availability”,不如检查“会议是否被正确安排”。前者评估的是执行路径,后者评估的是任务结果。
同时,评估也不应该只有完全成功和完全失败。一个能正确识别问题、完成大部分步骤、但在最后一步失败的 Agent,显然比一开始就失败的 Agent 更好。因此,可以设置部分得分,让指标反映 Agent 的渐进式改进,而不是只给出僵硬的通过或失败。